
Whisperを使って素材の自動書き起こし+素材分割 (ローカル実行)
注記:この記事で紹介しているスクリプト(下部で紹介)ですが、Whisper側の問題で正常に分割できないことが判明しています。対処方法はありますが少々面倒なのでスクリプト更新はずっとあとになる予定です。導入方法のみ参考にしてください。
目次
はじめに
みなさんごきげんよう。まいまいです。今回の記事では、今話題の音声認識AI、Whisperを使って素材の音声を自動書き起こしして、個別の音声ファイルに分割するスクリプトを作成したので紹介していきます。
音MADを作るとき、「あのセリフがほしい!」と思うこともあると思います。そんなときにセリフで分割したファイルを用意しておくと便利ですね。
この記事は、そこそこ良いパソコンを持っている人を対象にしています。具体的には数GB以上のVRAMを持ったCUDA対応のGPU搭載パソコンのユーザーです。
ローカルで実行することで、GoogleColabでの制限を気にせずに実行ができ、高精度な出力を追求できるのではと期待します。
実行環境がない人は大人しく後述するGoogleColabを利用してください。
Whisperとは
Whisperとは、OpenAIが開発した、音声認識AIです。いろんなAI開発してる会社のオープンソースの製品です。
自動音声認識ソフトには、GoogleやIBM、Amaoznなどいろいろな会社が開発していますが、このWhisperは、オープンソースで自由に使えることもあり、我々個人ユーザーにはとてもありがたいですね。
また、日本語の認識にも対応しており、日本語も高い精度での認識が可能になっているらしいです。
Web上で実行することも出来る
Whisperをローカルで実行するためには基本的にはCUDA対応のGPUが必要です。持っていない人はWeb上で実行可能なGoogle Colabを利用することになります。
いくつかGoogle Colabのノートは公開されていますが、E-tumさん公開のノートを利用すると良いと思います。

使い方等も書かれているのでそれに従ってください。
ローカル環境への導入
さて、ここからローカル環境に関する話になります。導入がそれなりに複雑なので、導入の説明だけで1§使います。
Pythonの導入
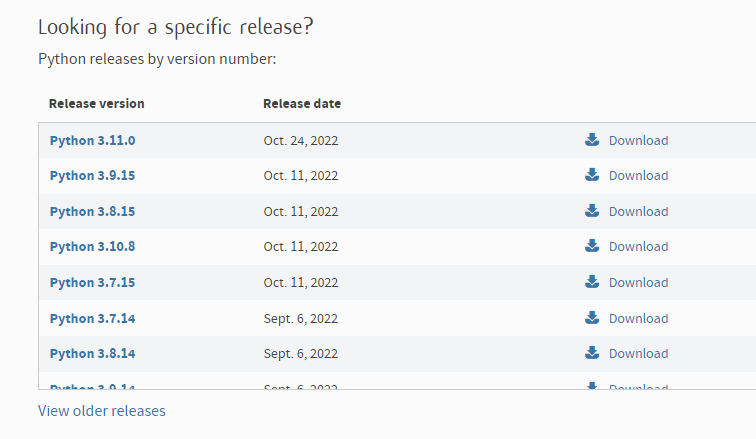
※リンク先の紹介記事では最新版のPython3.11を利用していますが、記事作成時点では3.11で実行できないようなんで、↓のリンク先から、Python 3.10.x又はPython3.9.xをダウンロードし、導入してください。
ffmpegの導入
解説を別ページに隔離しています
Gitの導入
次にGitを導入します。↓のリンクからインストーラーを入手し、デフォルト設定でインストール。
次にGitの導入先フォルダを環境変数に追加します。
上の記事のパスの通し方を参考にして、環境変数に
C:\Program Files\Git\bin
などのgit.exeがあるフォルダを追加します。その後PC再起動でGit導入は完了です。
Whisperのインストール
コマンドプロンプトを開いて以下のコマンドを実行します
pip install git+https://github.com/openai/whisper.git
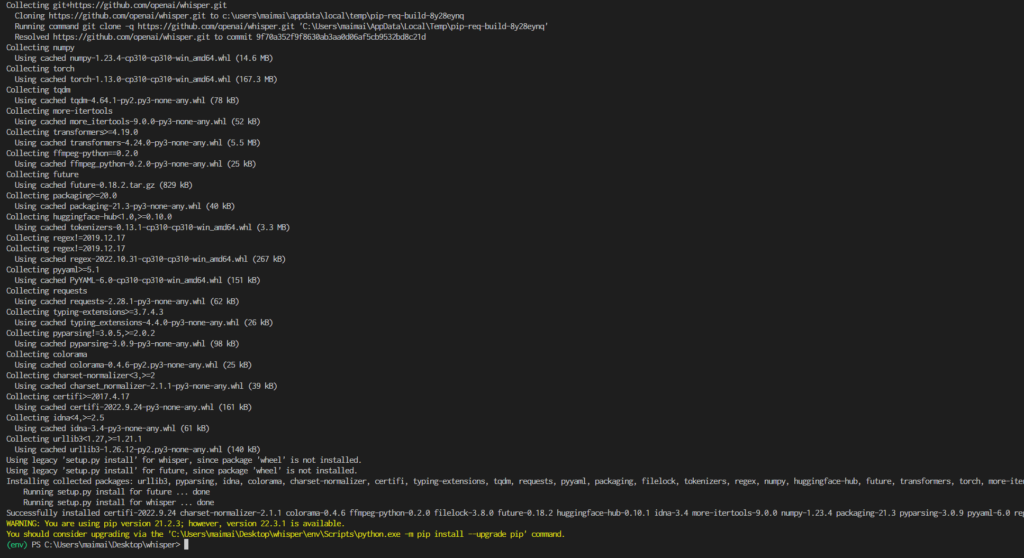
エラー出てなければ多分OK。
Whisperを実行
正常にWhisperが導入されているか確認するために、一度コマンドプロンプトでWhisperを実行してみます。
まず好きなフォルダに人の会話が入った音声ファイルを用意します。適当なアニメの音声でも切り抜けば良い。
長さは1分くらい?短めがいいです。
ファイルを用意したら以下のコマンドを実行します。
whisper [音声ファイルのパス] --model medium --language Japanese
正常に導入ができていれば図のようにモデルのダウンロードが始まり、ダウンロード完了後音声認識が始まります。Largeで実行するとモデルのファイルサイズも大きくなるので根気よく待ちましょう。ちなみに私は3回DL失敗しました。クソ回線め

問題が出てたら導入に失敗している可能性があります。問題があったらGIGAZINEの記事参考にしてみてください。
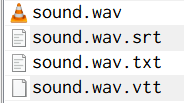
音声ファイルのフォルダにsrt, txt, vttの3種ファイルができていれば成功です。
Whisper補助スクリプト
はい。ようやくこの記事の本題です。
Whisperをローカルで(自分のパソコン上で)実行する際の補助用スクリプトを作成しました。
このスクリプトの設計思想は以下のとおりです
- largeモデルを利用し、可能な限り高精度な認識を行わせる。
- Whisperで誤認識が起こることを前提に、出力結果を一時ファイルに書き出し修正を容易にする。
- 動画作成時に映像を持ってこれるように、生成する音声ファイル名に元動画の再生時間を追加。
Github上で配布しています。
Githubの「Code」と書かれた緑色のボタンからZIPで保存できます
好きな場所に解凍して使ってください。
補助スクリプトの使い方
コマンドプロンプトで1-run-whisper.pyを実行します。

音声を選択し、暫く待つと音声認識の経過が表示されます
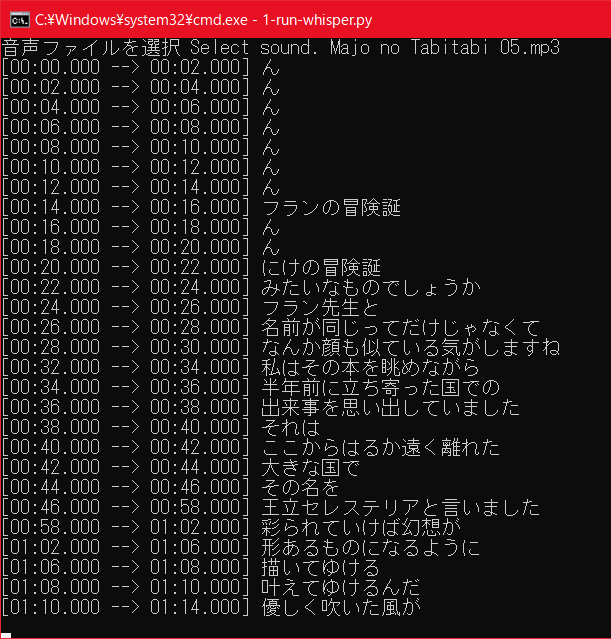
largeモデルを利用しているため、かなり時間がかかります。アニメ1話で20~30分くらい掛かってます。
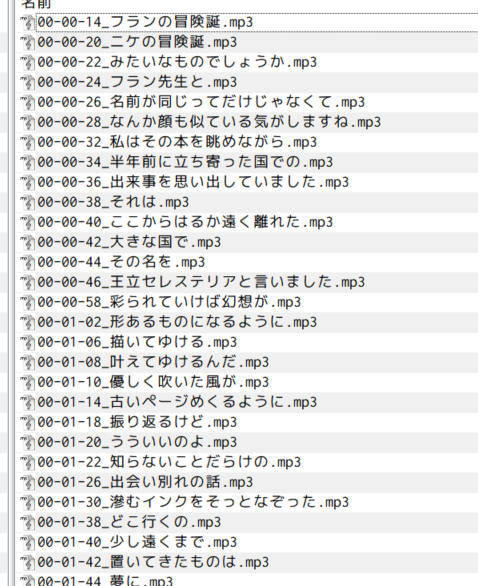
音声認識が終わると、音声ファイルのあるフォルダにsrt, txt, vttができ、実行フォルダにwhisper.csvが生成されます。
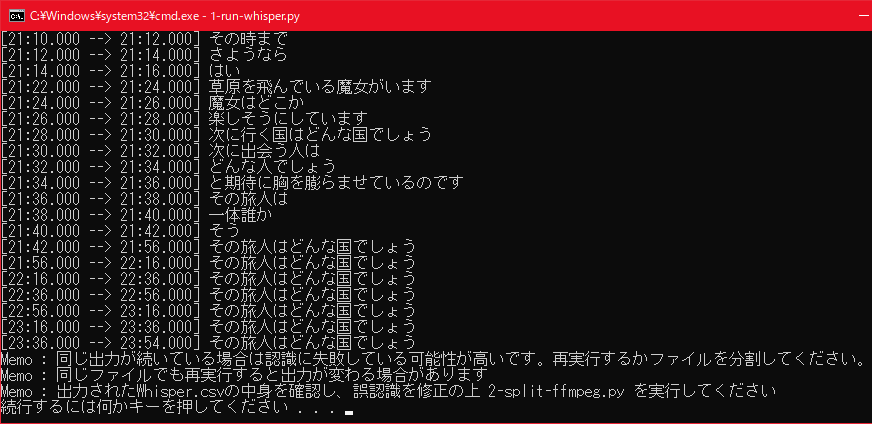
上の画像でもわかりますが、Whisperは若干認識をミスすることがあります。なので、出力されたWhisper.csvの中身を確認して誤認識を修正します。
ちなみに、私の環境では「ん」とだけ認識される現象が多発していますが、基本誤認識でした。
誤認識を修正したら、2-split-ffmpeg.pyを実行すると、セリフが分割され、出力されます。
Whisperの音声認識の問題点
Whisperの音声認識ですが、Largeモデルを利用しても誤認識があります。
単語が間違っている場合は修正が容易なのですが、下の画像のように、同じワードが何回も出力される場合があります。
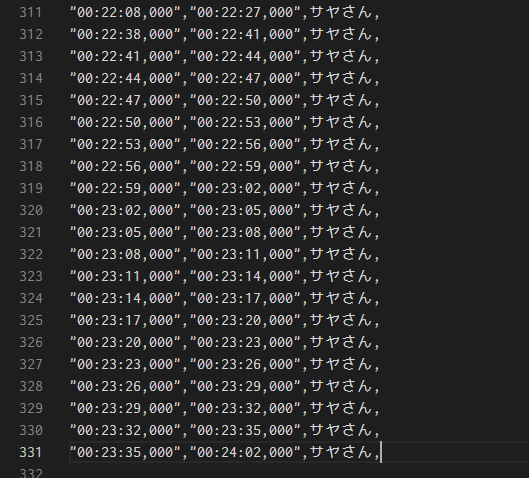
こうなった場合は、再度実行すると改善される場合があります。上手く行かない場合は該当範囲を別ファイルに書き出して再実行すると良いです。
[未検証]UVRやSpleeterでBGMを除去してから実行すると精度が落ちる?

上の2つを御覧ください。rawは音声無加工でWhisperを実行した際のファイル。uvrはUVRを利用してBRMを除去してからWhisperを実行した場合のファイルです。
SpleeterでBGM除去を行ってから実行した場合でも認識精度が下がっていました。
多少BGMがあっても除去せずにそのまま認識させたほうが良いのかもしれません。
今回の記事はここまで。私の動画の作風的にあんまり使い所が無いですが。作る動画の作風によっては大活躍しそうなツールですね。以上。ノシ
ツイート
コメントする?