
AIボーカル除去・抽出ソフト 「Ultimate Vocal Remover」の使い方と最良設定について
2023/01/13 追記
最新版ではこの記事で紹介しているものに加えいくつかの昨日が追加されています。使用の上でこの記事の内容で問題ありませんが、後日アプデ要素について追記します
目次
要旨
機械学習を用いたボーカル除去ソフト「Ultimate Vocal Remover」導入方法・使用方法を解説した上で、いくつかの学習モデルを用い複数条件でボーカル抽出を行い、ボーカル抽出に適したモデル・設定を追求した。その結果、VR Architectureメソッドの3_HP-vocalUVR.pthと、MDX-netメソッドのUVR-MDX-NET Mainモデルでのボーカル抽出が精度が高いという結論になった。両者でのモデルで抽出した後にManual Ensembleで合成するとより良い抽出となるかもしれない。
設定については、結論の項目のスクショを参考のこと。
また、楽曲でのボーカル抽出とは別に、BGMとして少量の音楽が流れた音声のBGM除去にUVRが利用できないか検証したところ、精度高くBGMを除去することができた。
序論
皆様ごきげんよう。まいまいです。久しぶりの更新です。今回の記事では近頃一部で激アツな、人工知能を用いたボーカル除去・抽出ソフトの「Ultimate Vocal Remover」(以下UVR)の使い方と最良設定について解説していきます。
私のブログでは、以前から人工知能を用いたボーカル除去・抽出ソフトの使い方などについて紹介してきました。
ブログで紹介してたソフトの他にも、izotope社のRXシリーズなど、様々なボーカル除去・抽出ソフトがありますが、今回紹介するUVRは最新のソフトなこともあり、特に精度が高くなっています。
導入方法
ソフト自体の導入は簡単ですが、導入前にお使いのPCがソフトに対応するかを確認しておきましょう。
UVRが動作するためには、以下の条件を満たすことが推奨されています。
- Windows10以降の64 bitOS(Mac,Linuxでも実行可能なようですが、この記事では扱いません。)
- 8 GB以上のV-RAMを搭載したNvidia製グラフィックボードが推奨
一応推奨スペックなので、満たさない環境でも実行できるかもしれませんね。私のちょっと古いPC(グラボなし)でも実行はできました。メッチャ時間かかりましたが。
さて、導入していきましょう。
https://ultimatevocalremover.com/
公式サイトのDownloadボタンのリンク先から最新版をDLします。
このソフトはバージョンによって仕様が色々変わっているようですが、記事作成時の最新版では、このリンク先からダウンロードするようです。

将来の版では導入方法が変わっている可能性もあるので頑張ってReleaseページを翻訳して探してください。
インストール方法は特に言うことはありません。Cドライブにインストールしましょう。
起動してみるとこんな感じ。
次のセクションで使い方を解説していきます。
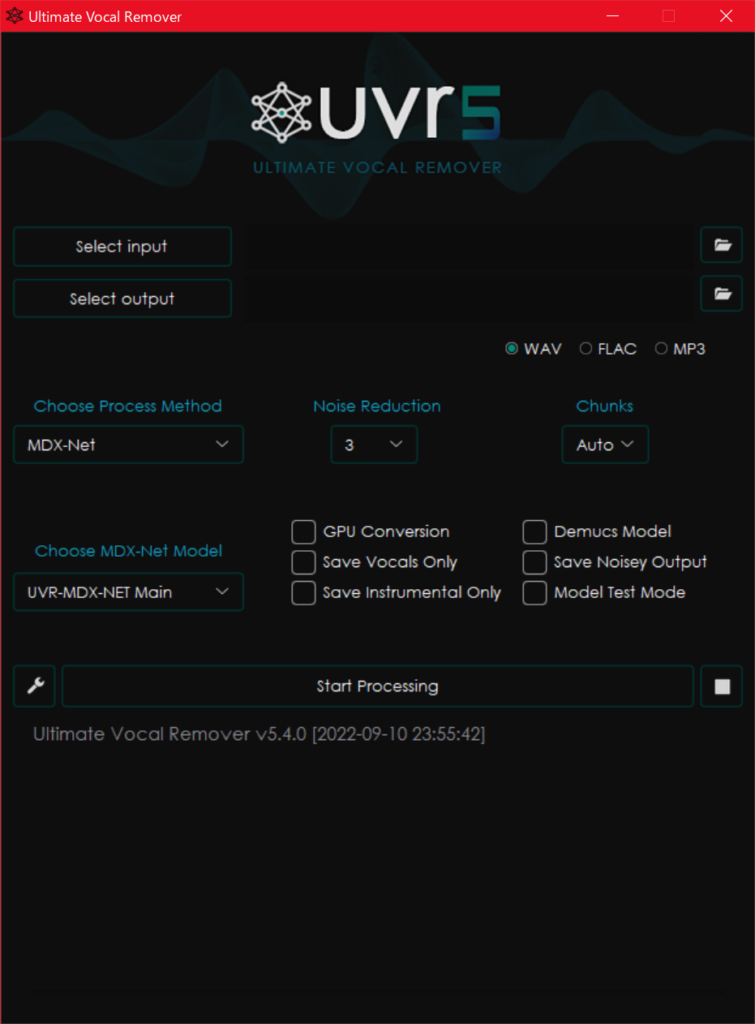
使い方
基本的な操作はごく単純です。まず画面左上の「select input」と「select output」でボーカルを抽出・除去したい曲を選択し、その下のProcess Methodで使用するAIネットワークを選択、Process Methodごとのモデルを選択。Start Processingで実行することができます。
曲の選択はドラッグアンドドロップでも追加可能です。
今回の設定では、wav形式で出力されますが、flacやmp3形式でも書き出しが可能です。ただしwav以外の形式で書き出すためにはffmpegを導入する必要があるので、基本wav書き出しで良いのではないでしょうか?設定方法の解説は省略します。
その他の設定は使用するAIネットワークによって設定項目が異なるので、ネットワークの説明とともに設定を説明していきます。
読みたくない人は結論まで飛ばしてオッケー
VR Architecture
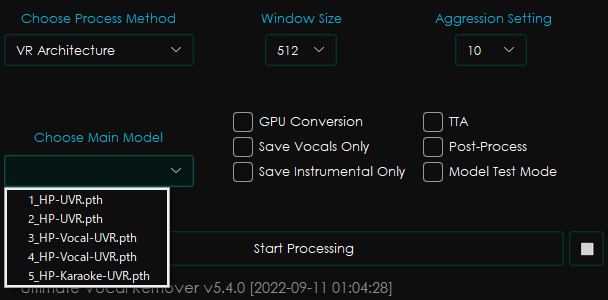
VR Architectureメソッドでは、基本5種、設定から追加モデルをダウンロードすると計25種のモデルを選択できます。
基本の5種のうち、1_HP-UVR.pthと2_HP-UVR.pthは曲からボーカルを除去するのに適したモデル、3_HP-Vocal-UVR.pthと4_HP-Vocal-UVR.pthは曲からボーカルを抽出するのに適したモデル、5_HP-karaoke-UVR.pthは曲からメインボーカルのみ(バックボーカルを残して)を除去するのに適したモデルのようです。
他の設定は以下の通り。
- Window size : 小さいほど高品質になるが、時間がかかるようになります。320だと高品質、1024だと低品質です。
- Agrettion setting : 音声のボーカル・曲除去の強さの設定です。デフォルトの10から変更する必要は無いです。
- GPU Conversion : GPUを使うかどうかの設定。CUDA対応のGPUでないと使用できません。
- Save Vocal/instrumental only : ボーカルかボーカル抜き音源のみを保存する設定です。
- TTA : “Test-Time-Augmentation”を使うことで分離の品質を上げるようです。ただし実行時間が長くなります。
- Model test mode : 複数のモデルを試したいときに有効にすると、出力ファイル名に使用モデル名が追加されます。
MDX-Net
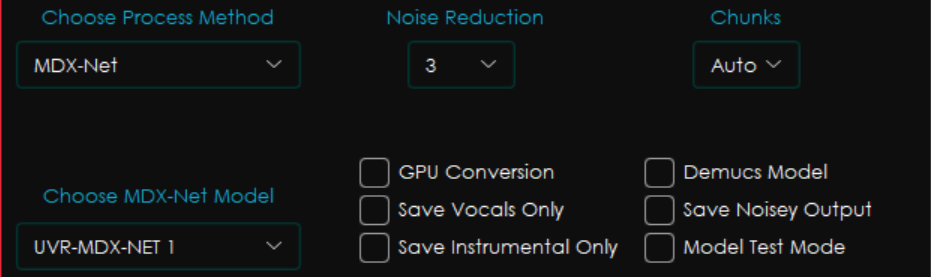
MDX-Netメソッドでは、基本5種、追加DLで計11種のモデルを選択できます。
基本5種のメソッドは、少しずつパラメータを調整したものが入っており、精度が高い順に、UVR-MDX-NET Main, UVR-MDX-NET 1~3の順になっています。~ KaraokeはVR Architectureのときと同じです。
他の設定は以下の通り。既に説明したものは省略します。
- Chunks : 使用するメモリ量を増減することができます。基本AutoでOK。
- Noise Reduction : 生じるノイズを低減する設定です。これもあまりいじらないでOK
- Demusc model : MDX-Netモデルに加えてDemucsモデルを使う設定です。ボーカル分離を改善するようですが、重くなるので私は有効にはしません。
Demucs v3 →最新版ではDemucs v4に変更
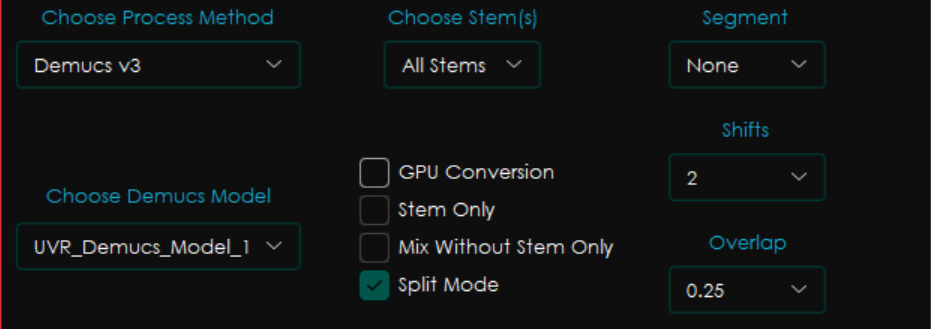
Dumucsは他のメソッドとは少々性質が異なります。上記2つのメソッドは楽曲からボーカルを抽出・除去することが目的ですが、Demucsは楽曲から楽器ごとにパート分けすることを目的としています。そのため弱冠設定項目が異なります。
Demucsでも、同様にデフォルトで入っているモデルと、追加でDLできるモデルがあります。
デフォルトで入っているのは、UVR データセットを用いて学習させた3種のモデルと、Demucsの開発陣が学習させたmdx_extraモデル2種です。
設定項目は以下の通り
- Choose stem(s) : Demucsはもともと曲をパート(stem)ごとに分けるモデルなので、ここで選択することができます。
- Segments : MDX-NetのChunksと同じ感じ
- Shifts : 入力値をちょっとずつ変えて平均化するらしい。GPUがない場合は0に設定したほうが良いらしい。
- Overlap : 曲を分割して計算を行うのですが、その分割部分をどれだけ重ねるか、という設定です。いじらなくてOK。
- Stem only : ステムのみを保存
- Mix Without Srem only : 曲と特定ステムを入力ファイルとして選択すると、曲からそのステムを除いた音声が出力されます。
- Split mode : Demucs v3独自のチャンク方式を使用します。
Ensemble Mode
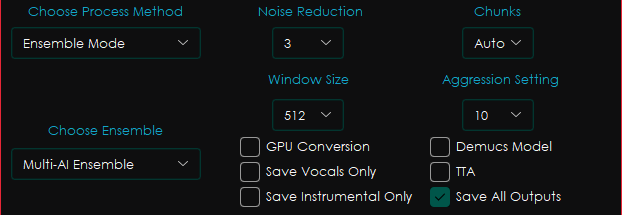
Ensemble Modeでは、これまで取り上げてきたモデルのうち、2つを組み合わせてボーカル抽出・除去を行います。
Multi-AI EnsembleではUVR_MDXNET_1と2_HP-UVR.pthの2つ、Basic VR Ensembleでは1_HP-UVR.pthと2_HP-UVR.pth、Basic MD EnsembleではUVR_MDXNET_MainとUVR_MDXNET_1を組み合わせます。
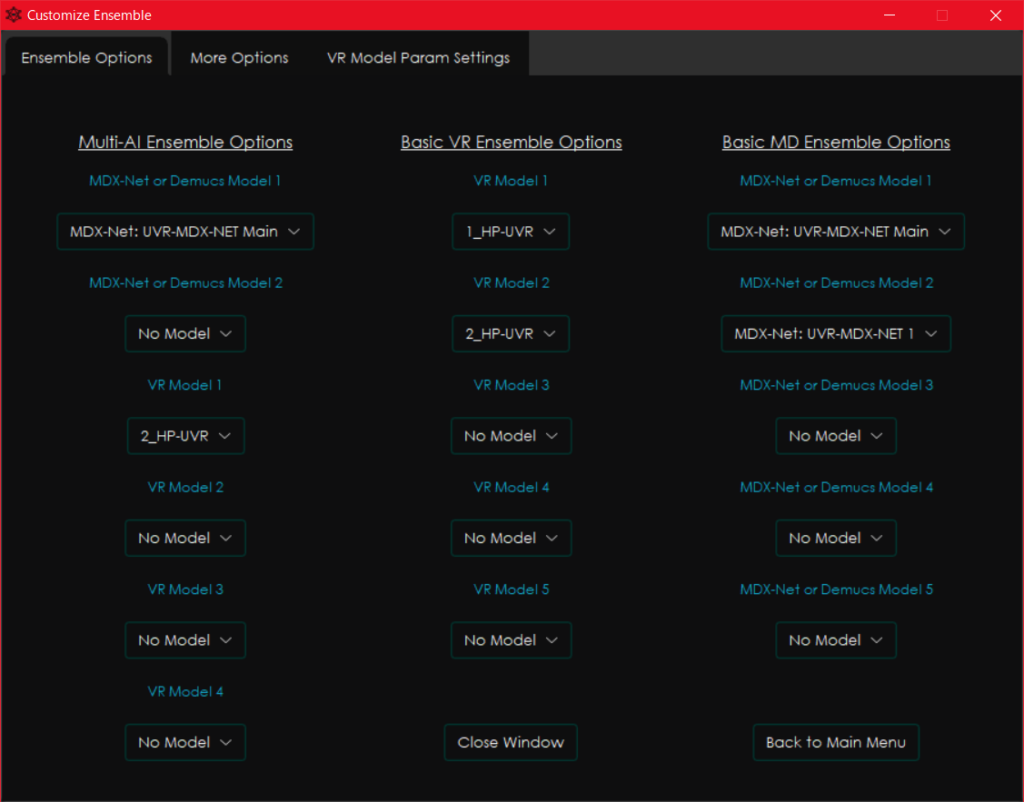
Manual Ensembleでは、Select Inputで、他モデルの出力結果のファイルを選択することで、複数モデルの出力を合成することができます。
ボーカル抽出に最適なモデルの検証
4曲の女声ボーカル曲(ゴシック調、Pops、FutureBass。肉声・ボカロ)、1曲の男声ボーカル曲で6種のモデルを用いてボーカル抽出を行い、以下の項目について減点方式で評価を行った。
- 原曲残り(ボーカル抽出しきれずに曲が残っている)
- ボーカル篭り(ボーカルを削りすぎて音がこもって聞こえる)
- ノイズ(抽出後音源にノイズが乗っている)
- ボーカル削れ
筆者の主観によるものであるので、ご承知おきください。
https://docs.google.com/spreadsheets/d/1wmJp1TExBAyG173YvBiJMLFeuMK97yURT2ADlRhlOuY/edit?usp=sharing
採点結果見ても仕方ないので、調査の結果わかった傾向を纏めます。
- 3_HP-UVR_(vocals)モデルとUVR-MDXNET_Mainモデルの精度が高い。
- RockやPopsのボーカル抽出は得意だが、ストリング音源が多い曲などは苦手(学習に用いた曲の方よりが原因?)
- 肉声とボーカロイド声ではそこまで抽出に大きな差は見られなかった
素材のBGM除去に使用できるか?
→できる。結構精度は高そうでした。
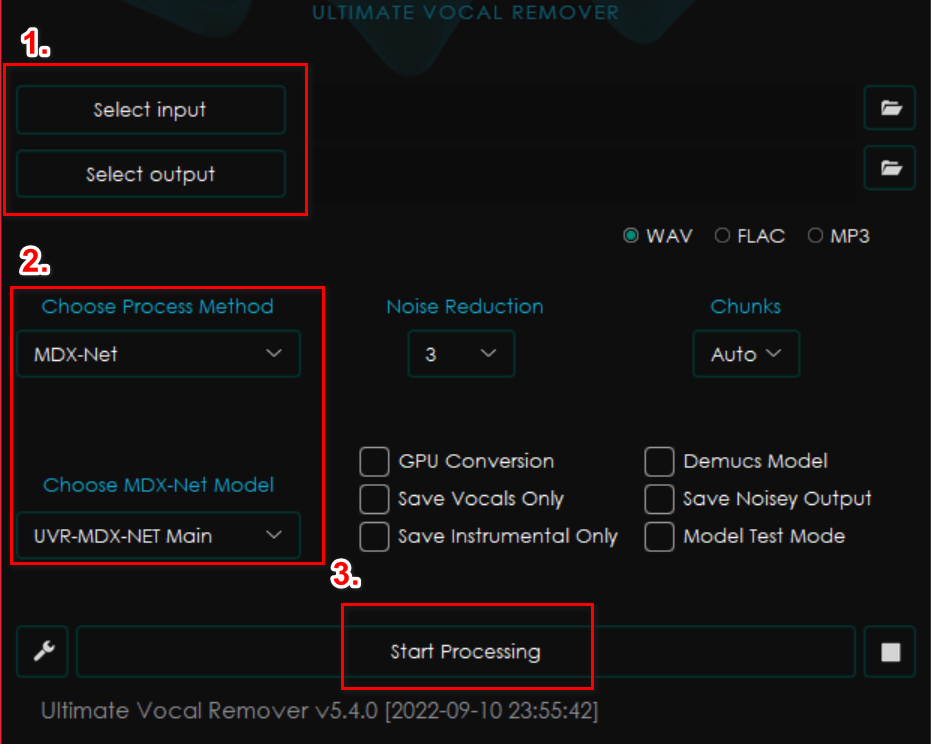
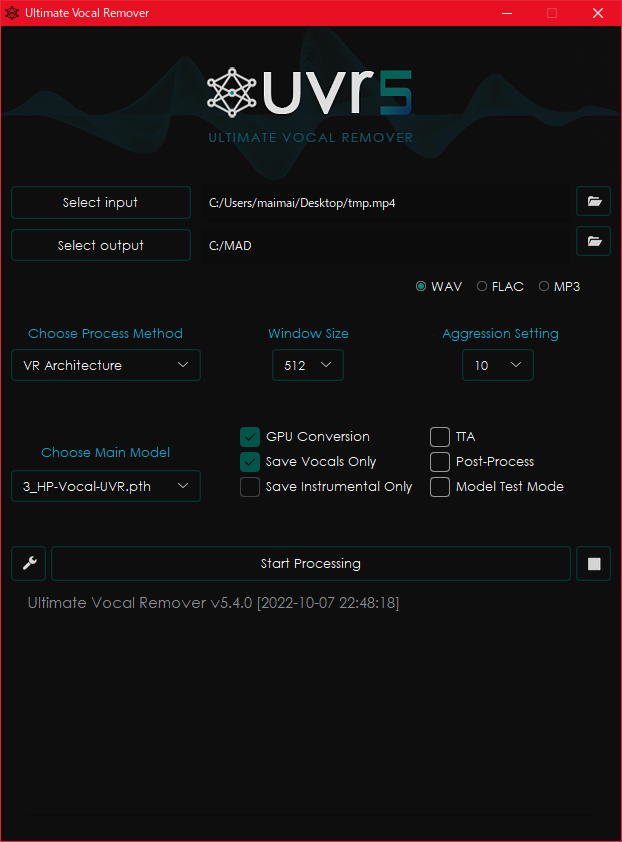
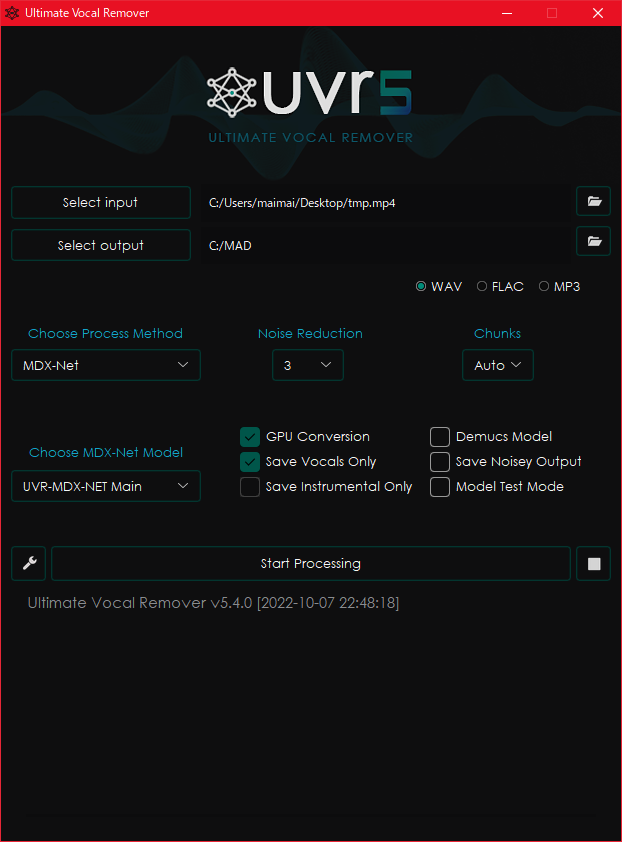
結論
使うときは以下のスクショのどっちかの設定にしておけばOK
コメントする?