
so-vits-svcで原曲のように歌わせる方法
みなさんごきげんよう。まいまいです。この記事ではso-vits-svcを使って歌わせる方法を解説します。
2023/03/11 requirements.txtの中身を修正しました。 scrpy==1.10.1に変更
目次
注意!
この記事は2023/03/05時点の情報を元にしています。今後の更新によって様々な所が変わる可能性があります。
2023/03/12 事情は知りませんが、本家レポジトリが削除されたようです。
今後はこちらのレポジトリを利用してください。ただし、この最新版レポジトリは当記事で紹介しているバージョン3系列ではなくバージョン4となっています。サンプリングレートが44100Hzに変更され、一部の使用法が当記事と異なっています。頑張って読み替えてください。
また、学習に必要な事前トレーニングモデルが現在提供されていないようです。これは更新され次第追記します。
はじめに
先日、音MADタグにこのような動画が投稿され、話題になりました。
動画を見ていただければ分かりますが、デスノートの夜神月の人力ボーカロイド系動画です。調声が尋常でなく上手で、まるで「原曲の歌手のように」歌っているように思えます。
実はこの動画は、投稿欄でも述べられている通り、so-vits-svcという人工知能を用いて作成されているようです。
so-vits-svcについてフワッと解説すると、音声や歌声を別の人の声に変換する話者変換技術の一種です。ボーカロイドやUTAU、ゆっくりやVoiceLOIDとは異なって、”もとの歌声、音声”が必要になります。まぁ超高性能なボイスチェンジャーみたいなものです。
この記事ではWindowsローカルでso-vits-svcを実行する方法を解説していきますが、かなり難解な記事となっています。Pythonに慣れていない人は挫折する可能性が高いのではないかと思います。覚悟して挑め。
おまけに公式が上げてるドキュメントも間違っていたり限定的な環境のみに対応していたりで厄介です。
また、機械学習を用いるので必要なパソコンのスペックはかなり高いです。RTX3060で若干力不足に感じるレベルです。
自力で環境構築ができない人や、推奨スペックに満たない人はGoogleColab版を利用してみてください。無料版では十分な学習ができない可能性はありますが…

さて、それでは順を追って導入していきましょう。
導入開始
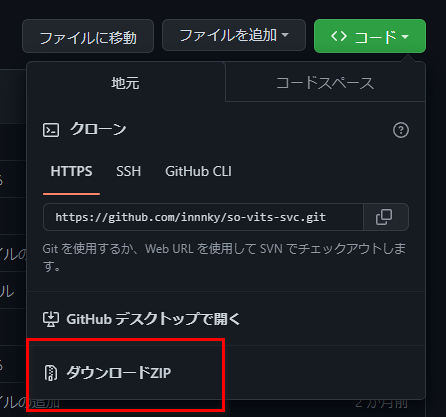
まずはso-vits-svcの公式Githubにアクセスし、レポジトリを丸々保存します。Git導入下ではgit cloneで保存します。導入してない場合は<>コードボタンからZIPで保存しましょう。
↓は削除された旧版へのリンク
次に事前学習済みモデルをダウンロードします。これがないと学習に時間がかかるらしい。
https://github.com/bshall/hubert/releases/download/v0.1/hubert-soft-0d54a1f4.pt
https://huggingface.co/innnky/sovits_pretrained/resolve/main/G_0.pth
https://huggingface.co/innnky/sovits_pretrained/resolve/main/D_0.pth
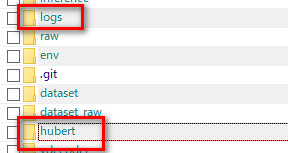
hubert-soft-0d54a1f4.ptは保存してきたレポジトリのhubertフォルダの中に、G_0.pthとD_0.pthはlogフォルダの32kフォルダのなかに入れます。
Pythonとモジュール類の導入
Python本体の導入
私が一番躓いたところです。
機械学習を用いたPythonスクリプトにありがちなことですが、使用するモジュールやPython自体のバージョンが重要になります。
まず、Python本体のバージョンですが、3.10を利用します。3.11では一部モジュールが使用できません。
別記事でインストール方法を解説しています。ダウンロード時に「view full list of downloads」から3.10のWindowsインストーラを保存し、実行して導入してください。
別バージョンのPythonがすでにインストールされている人も同様に3.10を入れてください。
Microsoft C++ Build Toolsの導入
これも必要なので導入します。
https://visualstudio.microsoft.com/ja/thank-you-downloading-visual-studio/?sku=BuildTools&rel=16
MSのサイトにアクセスし、ダウンロード。
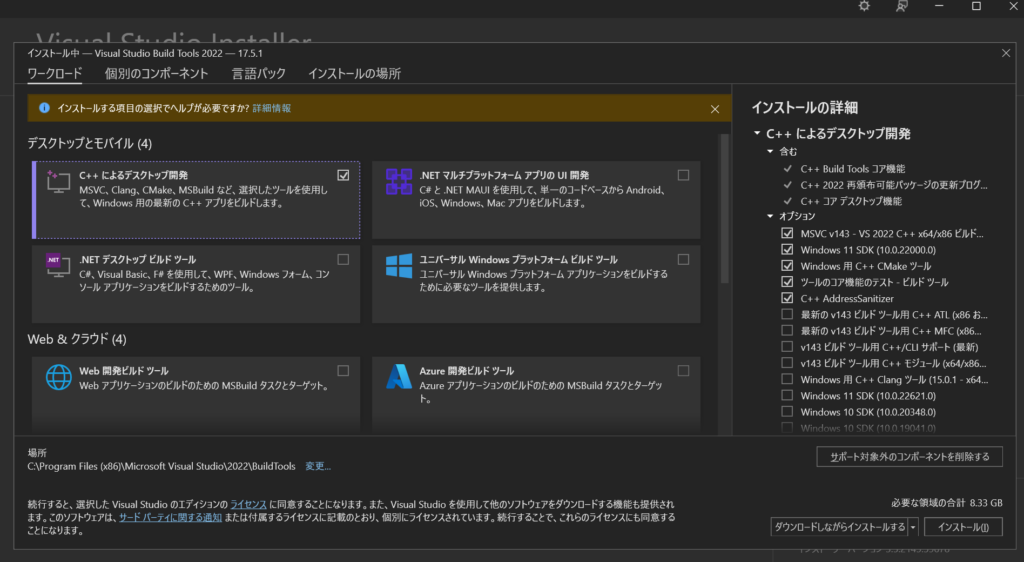
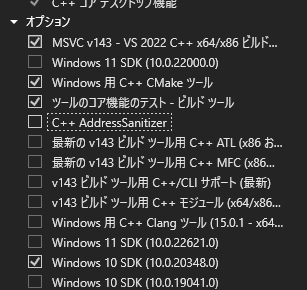
インストーラを実行しC++ BuildToolsだけを導入します。
必要なものは画像の通り。
Python仮想環境の作成
今回のようにバージョン依存の大きいモジュールを大量に使用する場合は、仮想環境を作成します。
特定のプロジェクト専用にモジュールをインストールする仕組みです。
コマンドプロンプトやPowerShellを開き、まず適当な作業用フォルダに移動します
cd C:\作業用フォルダへのパス\
次に仮想環境を作成します。envという名前の仮想環境を作ることにします。
python -m venv env
次に仮想環境を有効化します
env\Scripts\activate
すると
(env) C:\so-vits-svc>
のように行頭に(env)が付きます。これ以降の操作はすべて(env)がついた状態で実行してください。
別バージョンのPythonがすでにインストールされている環境の人は、以下のコードに読み替えてください。
py -3.10 -m venv .\env_py310 env_py310\Scripts\activate (env_py310) C:\so-vits-svc> python -V # バージョン確認を一応しておきましょう
モジュールの導入
公式Githubでは、必要なモジュールの一覧がrequirements.txtに記載されていますが、これは間違っています。
保存したレポジトリのrequirements.txtを開いて次のように書き換えます。
Flask==2.1.2 Flask_Cors==3.0.10 gradio==3.4.1 numpy==1.23.5 playsound==1.3.0 PyAudio==0.2.12 pydub==0.25.1 pyworld requests==2.28.1 scipy==1.10.1 sounddevice==0.4.5 SoundFile==0.10.3.post1 starlette==0.19.1 tqdm scikit-maad praat-parselmouth onnx onnxsim onnxoptimizer tensorboard librosa==0.8.1 matplotlib scikit-maad gradio
次のコードを実行してtorchを導入します
(env) C:\so-vits-svc> pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu117
そしてrequirements.txtに記載したモジュールを導入します、
(env) C:\so-vits-svc> pip install -r requirements.txt
上記のリスト以外にも必要なモジュールがあったりする可能性があるので、「not find module xxx」みたいなエラーが出たら都度
(env) C:\so-vits-svc> pip install xxx
を実行してインストールしてください。
素材の準備、前処理
素材の準備を行います。
使用する素材は以下の条件を満たす必要があります。
- 一つのファイルは5~10秒の長さのwavファイル
- サンプル数は最低100個、1000個程度有ると良い
- BGMや効果音が極力入っていない音声にする
- 話者は一人の音声を用いる(歌声である必要は無い)
用意したwavファイルは、dataset_rawフォルダの中に好きな名前(英字)のフォルダを作り(例ではspeaker0)、その中に入れます。フォルダ形式はこんな感じにします。ファイル名は適当で良さそう?変なところでエラーが出たら嫌なので、英数字と-_で構成されたファイル名にしましょう
今回私は、1000個の5~10秒程度の音声ファイルを用意しました。
dataset_raw
└───speaker0
├───xxx1-xxx1.wav
├───...
└───Lxx-0xx8.wav
wavファイルを用意したらデータセット(学習させる音声集)を作成します。
音声ファイルのリサンプリング
(env) C:\so-vits-svc> python resample.py
dataset/32k/speaker0に変換ファイルが生成されます。
(env) C:\so-vits-svc> python preprocess_flist_config.py
configs/config.jsonに設定ファイルが生成されます。
(env) C:\so-vits-svc> python preprocess_hubert_f0.py
何かわからないけど必要なファイルを生成しています。
これでデータの前処理は完了です。
設定変更
各自の環境によって設定を書き換えます。
configs/config.json開き、以下の項目を変更します。
batch_sizeをVRAM容量に応じて変更。16GB 以上のVRAMがある場合はデフォルトの12、RTX3060 VRAM12GBの場合は10に、それ以下のVRAMの場合は適度に減らしましょう。epochsを400に(1000サンプルの場合)。この項目で学習時間が変わります。120エポックでも十分って話を見かけたので、そのくらいに減らしても良いかもしれません。
学習実行
学習を実行します。
(env) C:\so-vits-svc> python train.py -c configs/config.json -m 32k
めっちゃ時間かかります。私の環境(RTX3060)では、3.5hかかりました。
途中でG_1000.pthのように中間ファイルが生成されます。それ以降なら途中でCtrl+Cで中断させても途中から学習を再開できます。中間ファイルでもモデルとして使用できます。一つの中間ファイル生成まで20分位かかりました。
私はミスって1000epochsで実行する設定にしたので途中で切り上げました。
うまく行っていればこんな感じのログが出るはず。
前略 INFO:32k:Train Epoch: 1 [0%] INFO:32k:[4.424172401428223, 2.0833280086517334, 14.009364128112793, 53.19264602661133, 13.062368392944336, 0, 0.0001] INFO:32k:Saving model and optimizer state at iteration 1 to ./logs\32k\G_0.pth INFO:32k:Saving model and optimizer state at iteration 1 to ./logs\32k\D_0.pth INFO:torch.nn.parallel.distributed:Reducer buckets have been rebuilt in this iteration. INFO:32k:====> Epoch: 1 INFO:32k:Train Epoch: 2 [72%] INFO:32k:[2.481069803237915, 2.4920921325683594, 11.151412963867188, 24.0196475982666, 1.287828803062439, 200, 9.99875e-05] INFO:32k:====> Epoch: 2 INFO:32k:====> Epoch: 3 INFO:32k:Train Epoch: 4 [45%] INFO:32k:[2.5487236976623535, 2.8654420375823975, 12.654862403869629, 24.38988494873047, 1.344555377960205, 400, 9.996250468730469e-05] INFO:32k:====> Epoch: 4 INFO:32k:====> Epoch: 5 INFO:32k:Train Epoch: 6 [17%] INFO:32k:[2.1616806983947754, 2.5084800720214844, 14.937881469726562, 25.60817527770996, 1.1187540292739868, 600, 9.993751562304699e-05] INFO:32k:====> Epoch: 6 INFO:32k:Train Epoch: 7 [90%] INFO:32k:[2.3947222232818604, 2.2997708320617676, 12.498693466186523, 24.691783905029297, 0.8341096043586731, 800, 9.99250234335941e-05] INFO:32k:====> Epoch: 7 INFO:32k:====> Epoch: 8 INFO:32k:Train Epoch: 9 [62%] INFO:32k:[2.286954641342163, 2.5008175373077393, 12.373826026916504, 23.42261505126953, 1.4797286987304688, 1000, 9.990004373906418e-05] INFO:32k:Saving model and optimizer state at iteration 9 to ./logs\32k\G_1000.pth INFO:32k:Saving model and optimizer state at iteration 9 to ./logs\32k\D_1000.pth INFO:32k:====> Epoch: 9
学習データはlogs\32k\に.pth形式で生成されます。
生成モデルの使用
うまく学習が行われたと仮定して、モデルを使用していきましょう。
まず、レポジトリのフォルダにcheckpointsフォルダを作成しその中にさらに、適当な名前のフォルダを作成します。ここでは”name”フォルダを作成しました。そしてlogs\32k\に生成されるG_xxxx.pthをコピーし、model.pthに変更します。
次に、 logs\32k\に 生成されるconfig.jsonも同じフォルダにコピーします。
そして以下のコードを実行します。
(env) C:\so-vits-svc> python sovits_gradio.py
すると、ローカルでgradioが実行されるので、表示されるURL(ここではhttp://127.0.0.1:7860/)にアクセスします。
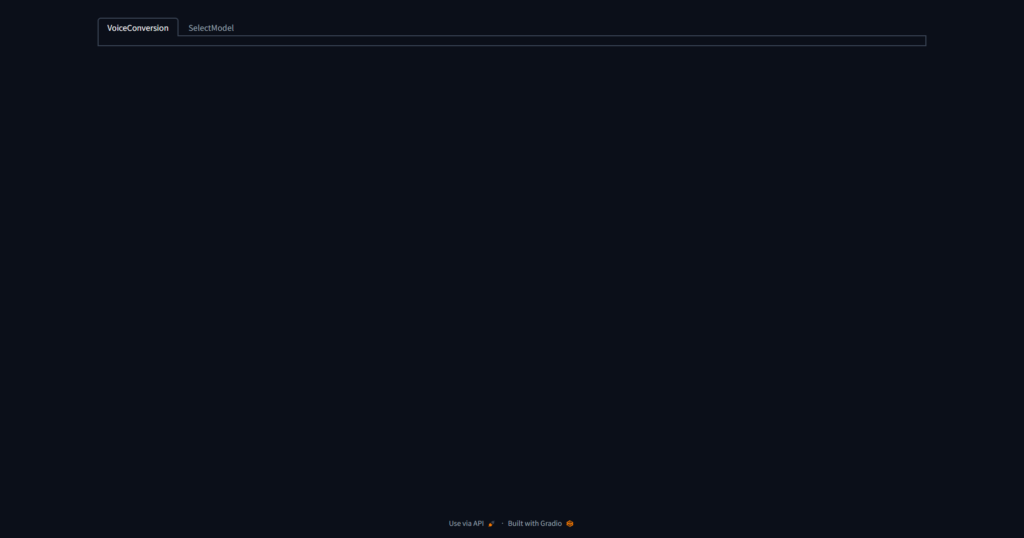
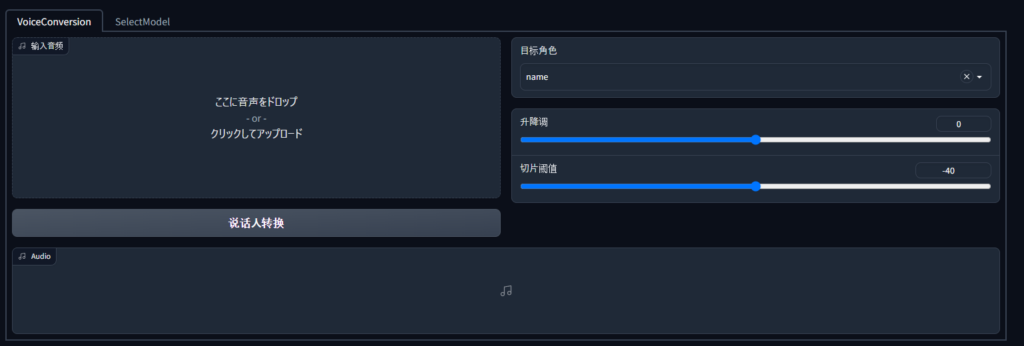
すると次のような画面が表示されるので、SelectModelタブを開き、モデルとCPU/GPUの選択を行います。
载入模型ボタンを押すとモデルが読み込まれるので、VoiceConversionタブに移ります。
ここに音声をドロップ、をある領域にボーカル音声を読み込み、说话人转换ボタンを押します。すると変換が実行され下部で再生が可能になります。
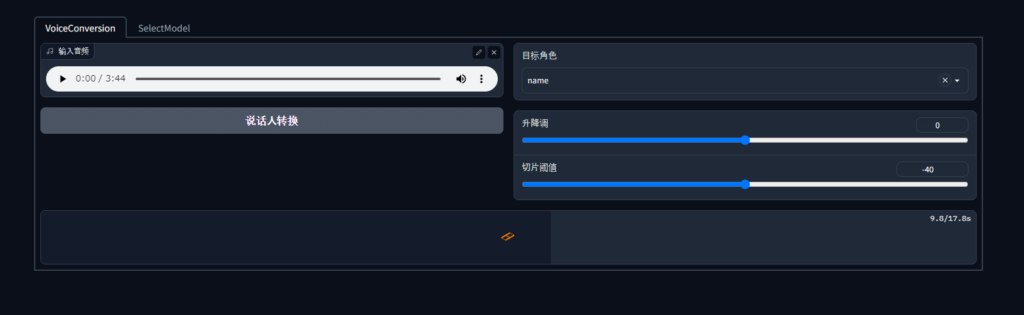
この変換はそこまで時間はかからず、30秒程度で生成されました。
生成されたものを聞いてみましょう。
結構すごいですね。ただしデータセットが良くなかったのか、子音が若干甘いようです。
また、使用するボーカル音声も、コーラスパートが入っていると生成は難しそうでした。これは仕方ないですね。
所感
音MADに使うにはデータセット作成のための素材収集が大変すぎるように感じた。何回も同じ人/キャラクターに歌わせるなら有用な方法かもしれません。ボーカル音声の抽出も高品質なものが必要になるなど、かなりハードルが高く思えました。
音MAD界隈で流行るか、微妙ですね。
さいごに
この記事を読んで、何故かうまくいかない!となった人は、まずは自分でGoogle検索して解決法を模索してみてください。
また、以下のサイトにバグと対応法の情報が沢山まとまっているので、問題に遭遇したら読んでみると良いかもしれません。

参考文献

戯言
人の手で作られてないから「人力」ボーカロイドではないな!
ツイート